


Let’s speed things up.
Parallelism settings and how to accelerate your database performance.
Few days ago, when performing a routine audit for our client, we noticed that parallel queries in the database were disabled. It wouldn’t be surprising but it’s important to note that our client has powerful servers that run not only lightweight OLTP queries. When we brought it to our client’s attention his first question was «How can we enable it?» and after that he reasonably added «Will there be any negative consequences if we do?»
This kind of question pops up more often than one thinks, hence this post where we look into parallel queries in detail.

Parallel queries were introduced 2 releases ago, and some significant changes were made in Postgres 10, thus a configure procedure in 9.6 and 10 is slightly different. Also, in the upcoming Postgres 11, there are several new features added related to parallelism.
Parallel queries feature has been introduced in Postgres 9.6 and is available for a limited set of operations such as SeqScan, Aggregate and Join. In Postgres 10 the list of supported operations has been broadened to: Bitmap Heap Scan, Index Scan, Index-Only Scan. Postgres 11 (hopefully!) will be released with the support of parallel index creation and support of parallel DML commands that create tables, such as CREATE TABLE AS, SELECT INTO and CREATE MATERIALIZED VIEW.
When parallelism has been introduced in 9.6 it has been disabled by default, but in Postgres 10 it has been enabled — our client’s database runs on 9.6, so this explains why it was disabled. Depending on the Postgres version there are 2 or 3 parameters which enable parallel queries and they are located in postgresql.conf in the «Asynchronous Behavior» section.
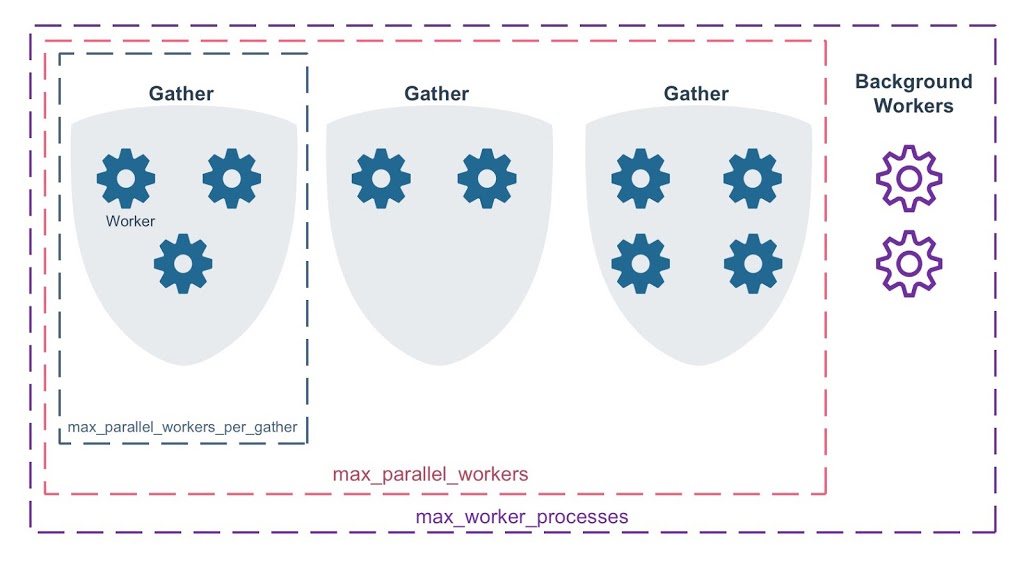
The first one is max_worker_processes which has been added in Postgres 9.4 and sets the limit of background processes that Postgres can run (the default is 8). It includes background workers and doesn’t include system background processes such as checkpointer, bgwriter, wal senders/receivers, etc. Note, that to change this parameter the Postgres needs to be restarted.
The second parameter is max_parallel_workers_per_gather, which is 0 by default in Postgres 9.6 and means that parallel queries feature is disabled. To enable it, it must be greater than 0. In Postgres 10, the default value has been changed to 2. This parameter defines maximum number of allowed workers per single parallel query.
The third parameter is max_parallel_workers, added in Postgres 10 and defines maximum number of workers only for parallel queries, because of max_worker_processes also relates to the background workers.
- max_worker_processes = 12
- max_parallel_workers_per_gather = 4
- max_parallel_workers = 12
These settings allow to run at least 3 parallel queries concurrently with maximum of 4 workers per query, and to have 20 cores for other, non-parallel queries. If using background workers max_worker_processes should be increased accordingly.
That, of course, is not all the parameters that need to be taken into consideration when deciding between parallel and non-parallel queries. In «Planner Cost Constants» section of postgresql.conf additional advanced settings can be found.
parallel_tuple_cost and parallel_setup_cost define the extra costs that being added to the total query’s cost in case of using parallelism. Another one is min_parallel_relation_size which is only available in Postgres 9.6, it defines a minimal size of relations that can be scanned in parallel. In Postgres 10, indexes also can be scanned in parallel, so this parameter has been split to min_parallel_table_scan_size and min_parallel_index_scan_size — that allow to perform same action for tables and indexes respectively.
In general, cost parameters can be leaved as is. Their configuration might need a little bit of adjustment in rare cases for tuning of particular queries.I’d also like to mention that in Postgres 11 parallel index creation will be introduced and additional parameter will be added — max_parallel_maintenance_workers that defines the maximum number of workers used in CREATE INDEX command.
Do you use parallelism? Did you have any issues using it? Would be great to hear your thoughts!



